
Background
When I applied to SweetSpot in 2014, my technical interview included building and refactoring a ruby script capable of calculating an interquartile mean. The tricky part was that it should recalculate as new numbers are added to the data set in an optimal manner.
- Can you optimize the recalculation?
- Can you make the code readable and maintainable?
- Can you make it extensible for a larger application?
I approached the optimization by turning the data into a histogram which allowed me to quickly triage what was inside and outside of the 2nd and 3rd quartiles, cutting down on recalculating the mean from the entire data set.
The readable/maintainable part is visible in the GitHub link; I also turned the code into a gem which you could include as part of a Ruby web application.
JRuby
I heard about JRuby at RubyConf 2014 and wanted to try it out with something. My thought was I could parallelize the IQM calculation by distributing the data set to a series of parallel workers from a pool. Once each worker was done, it would report it’s own IQM and they would all be averaged (this does not give a 100% correct answer but I was more interested in working with JRuby at this point).
I created a similar approach in MRI Ruby with Threads, with the caveat that the threads still run in the same Ruby process and there is a bottleneck at the Global Interpreter Lock.
Dataset size vs. margin of error
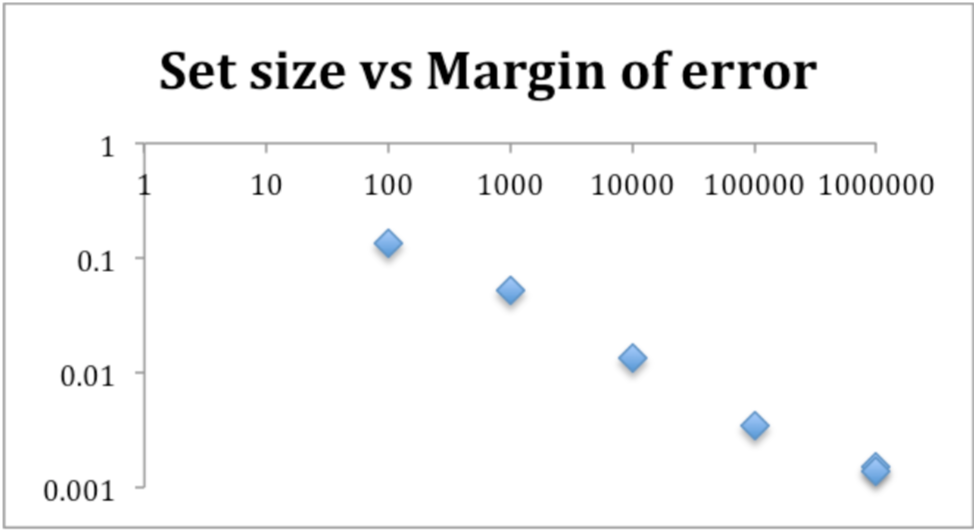
This one is purely mathematical. The larger the data set, the more we approximate the true average in subsets (assuming the number of sets is held constant).
Number of workers vs. margin of error
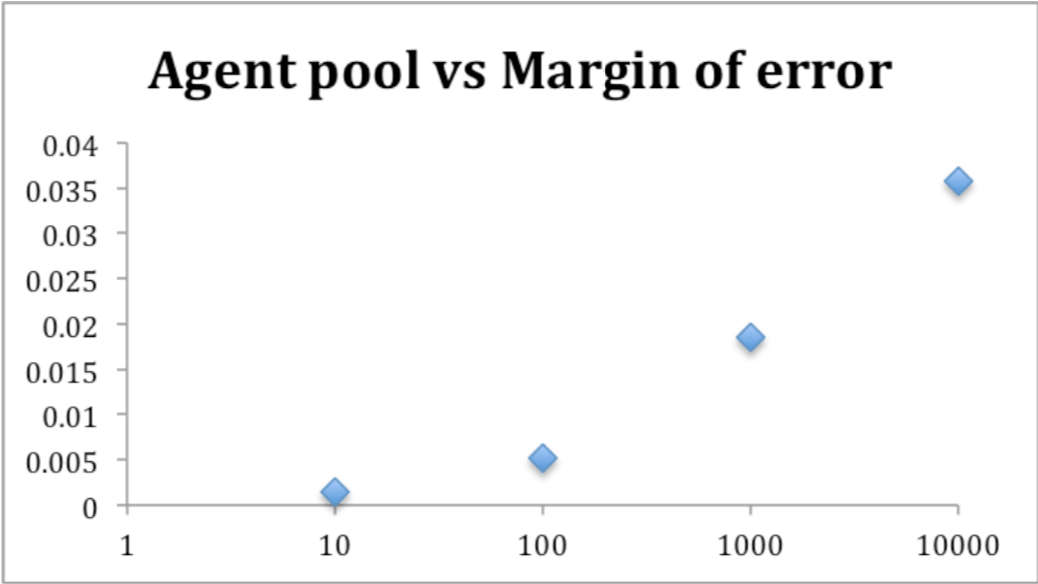
Again, these results are mathematical. More agents = more disparity within each agent’s set. As a sanity check, I got the same results for these regardless of using MRI Ruby or JRuby.
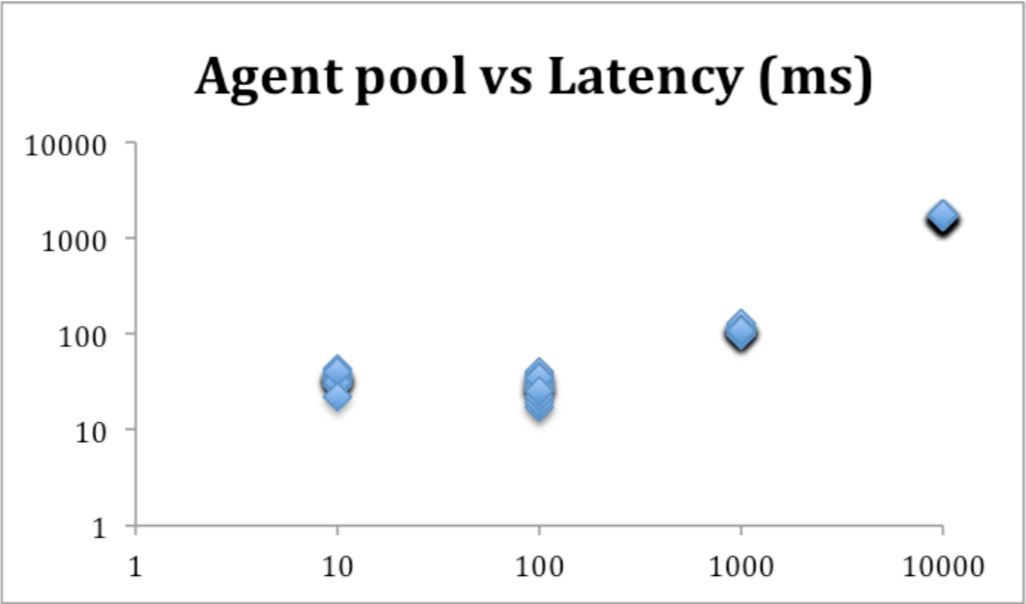
Ruby implementation vs. speed
What I was more interested in was: is JRuby faster at doing these calculations, given that it’s using threads across multiple cores, instead of MRI on a single core.
JRuby
MRI
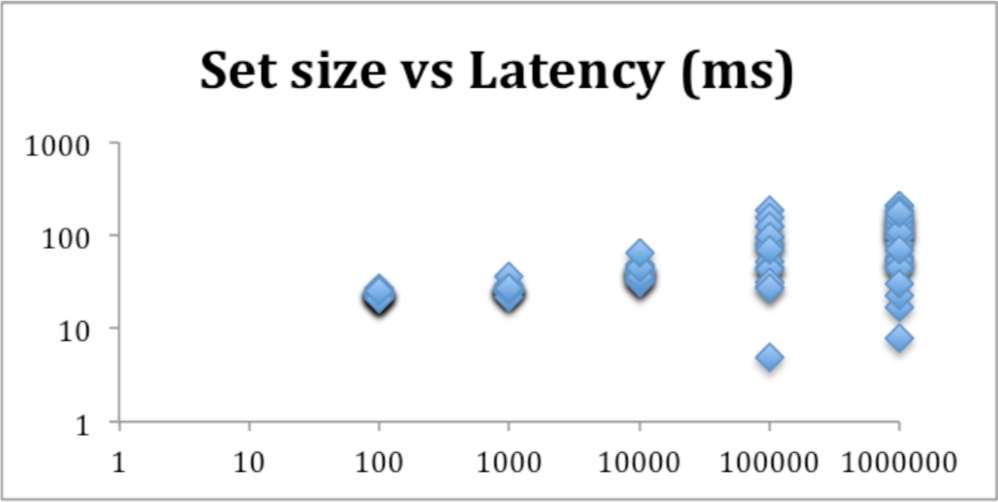
No real difference. That was disappointing.
However, I did re-run for very large data sets where I started to see a trend.
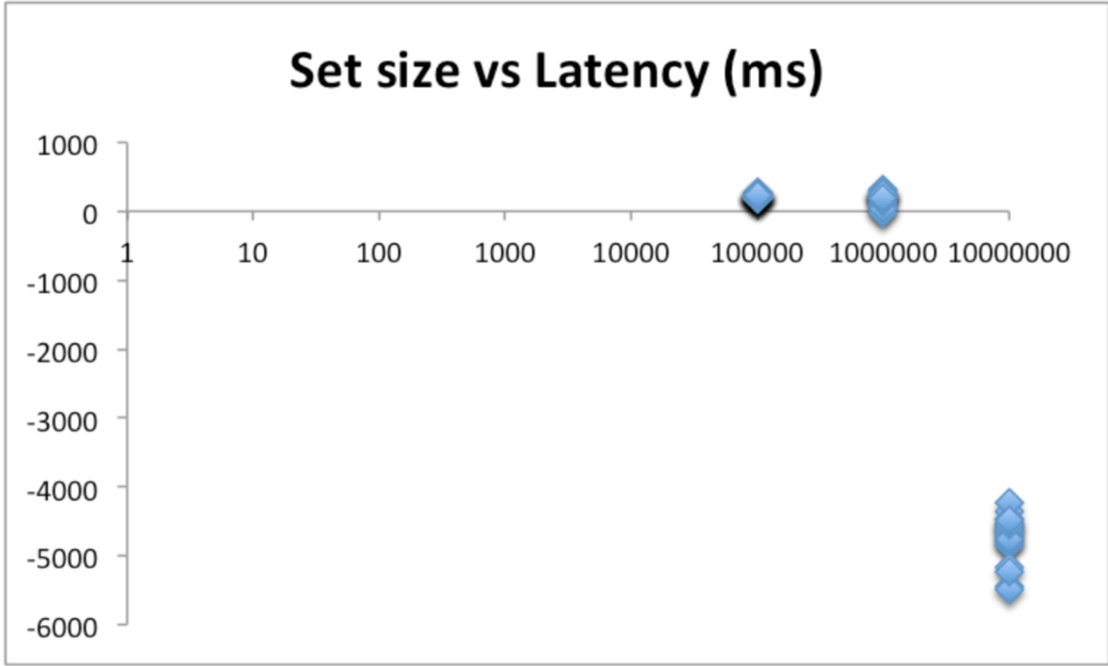
Here, I’m showing the results of JRuby while compared to a baseline of MRI Ruby. It does look like when you reach large data sets, JRuby might be doing enough to make a difference. More investigation would be required but there is a glimmer of hope.